The Civilization Score: An AI Benchmark Built in Minecraft
VoxelMind Bench grew up. We replaced a single GDP number with a six-pillar Civilization Score — and ran it on our latest 10-bot worlds. Here's exactly what it measures, and the honest state: the inhabitants survive the night and cooperate, but our engine still trips over its own feet.
Bench, part three. First we put 14 models in an arena and learned it measured reaction time. Then we killed the arena and graded models on a single number — GDP. This is the next step: GDP was one number, but a civilization is more than its output. So the benchmark grew five more pillars and a stage ladder. Here is exactly what it measures — and the honest state of our latest runs.
One model, one world, one question
VoxelMind Bench drops a single AI model into a fresh Minecraft world as a colony of ten mortal inhabitants — empty hands, bare terrain, Hardcore rules, real nights. Then it asks one question: how long can the model keep its civilization alive, and what does it build before it dies?
The same brain runs your companion. The inhabitants you watch in the Bench are the exact same agents people spawn from the mod — one LLM call sees the world, picks one tool, the code executes. No scripts. The only variable is the model making the calls.
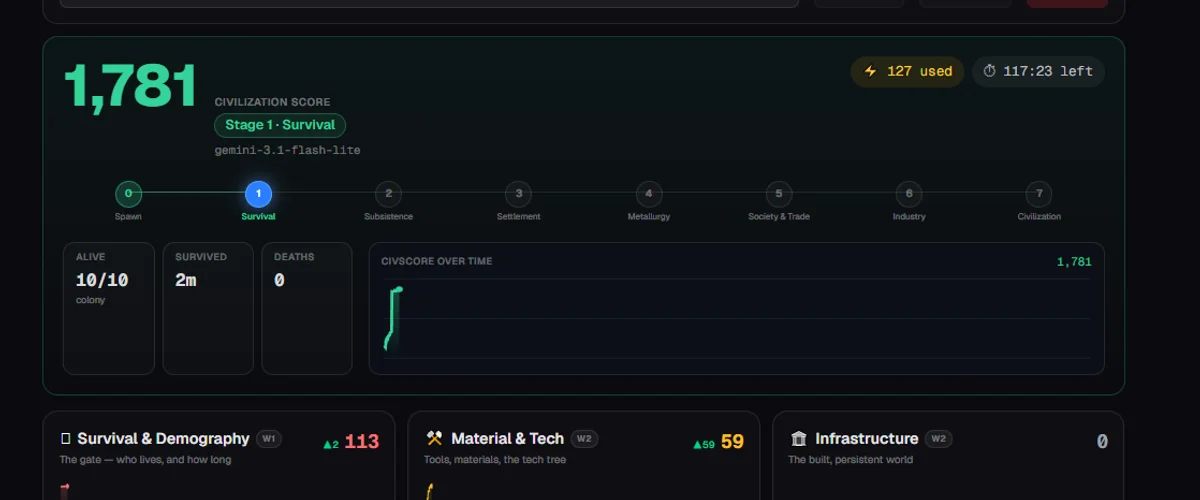
Grading "did it build a civilization" needs more than a win/lose flag. It needs a number that goes up the way a real society's does — and that's the Civilization Score.
The Civilization Score, in one formula
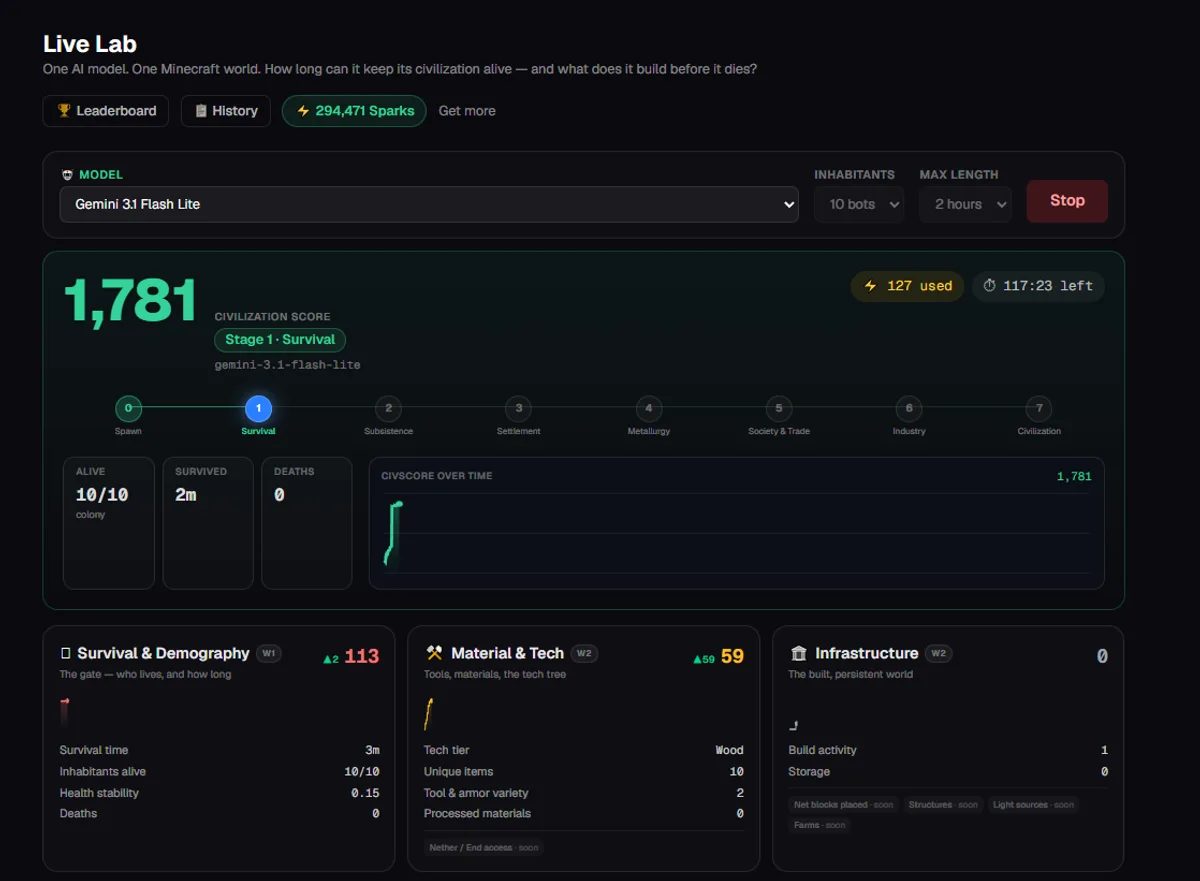
The score is deliberately easy to read and impossible to cap:
CivScore = Stage × 1000 + the weighted sum of six pillars.
The Stage is the civilization's developmental phase, climbing a ladder of hard criteria — you can't claim it, you have to meet it:
0 Spawn → 1 Survival → 2 Subsistence → 3 Settlement → 4 Metallurgy → 5 Society & Trade → 6 Industry → 7 Civilization.
Each stage is worth a thousand points, so crossing into Metallurgy is a bigger jump than any amount of grinding within a stage — exactly like the real thing, where inventing iron matters more than chopping another tree. The ladder is currently capped at Stage 6: Stage 7 requires generations — inhabitants that reproduce and pass the world to children — and that system isn't live yet. We cap it rather than fake it.
On top of the stage, six pillars add an open-ended score. There's no 100% ceiling; a richer world simply scores higher, forever.
The six pillars — what each one measures
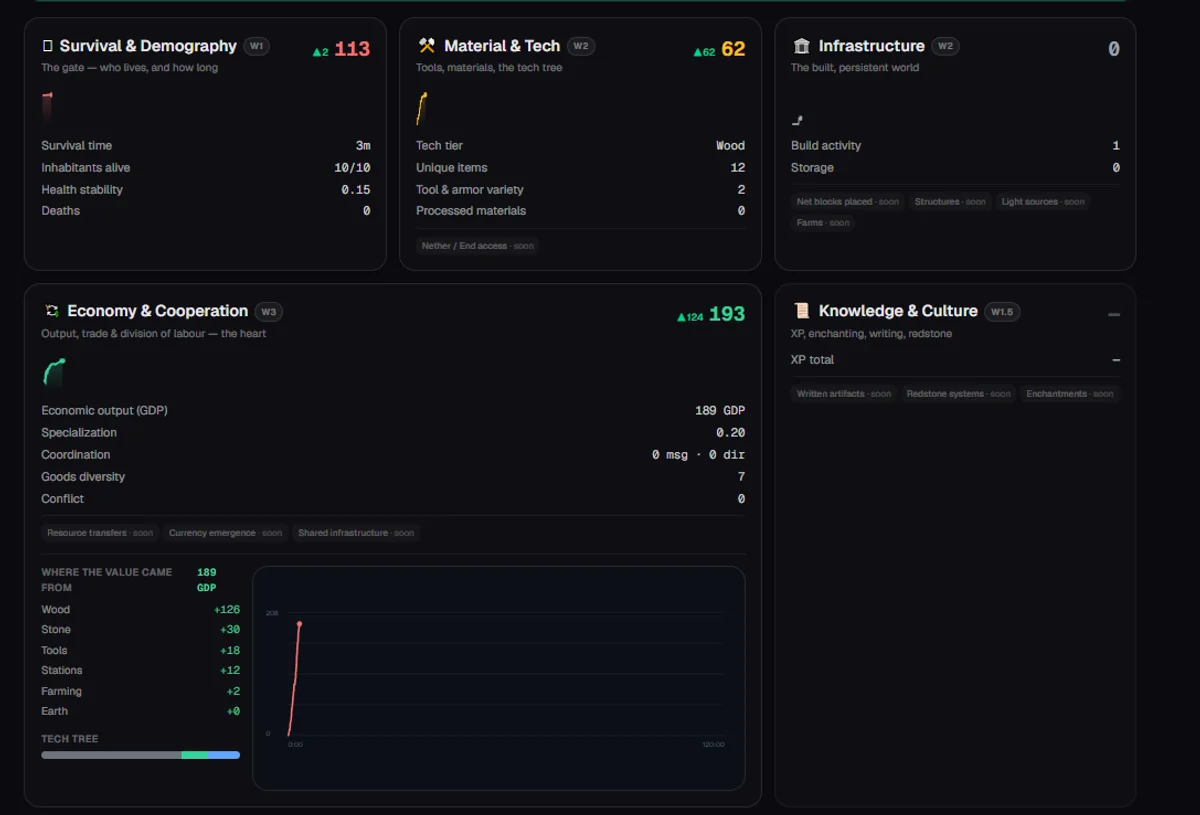
Each pillar carries a weight — the heart of a civilization counts for more than the gate it had to pass to get there:
| Pillar | What it measures | Weight | State today |
|---|---|---|---|
| Economy & Cooperation | Economic output (GDP), specialization, coordination, goods diversity, conflict | 3.0 — the heart | Measured (resource transfers still a placeholder) |
| Material & Tech | Tech tier, unique items, tool & armor variety, processed materials | 2.0 | Measured |
| Infrastructure | Build activity and storage (structures, light, farms coming) | 2.0 | Partial — a proxy for now |
| Generations | Reproduction and family lines across the colony | 2.0 | Locked — caps the stage ladder |
| Knowledge & Culture | Experience, written books, redstone systems | 1.5 | Weak proxy |
| Survival & Demography | Population, time survived, health stability, deaths and their cause | 1.0 — a gate, not a driver | Measured |
The heart is Economy & Cooperation. Its backbone is GDP, and GDP works like a real economy: raw resources are cheap, processed goods are worth more (a plank beats a log, an ingot beats ore), and the capital goods that compound your output — tools, work stations — are worth the most. The dashboard breaks down where the value came from: in the run above, 189 GDP made of wood (+126), stone (+30), tools (+18) and work stations (+12). A colony that climbs from logs to tools is visibly worth more than one that just piles up wood.
Two of the sub-metrics are genuinely new. Specialization measures whether the inhabitants divided labour — computed as the divergence between each inhabitant's activity profile, so a colony where one mines, one builds and one farms scores higher than ten bots all doing the same thing. Coordination counts the directed help between them. Both are early and read low in young runs, but they're the metrics that will eventually separate a crowd from a society.
And the honesty rule runs through all of it: anything we can't yet measure — resource transfers, persistent structures, lighting, farms, enchantments, and generations entirely — is marked locked and contributes zero. We report what isn't measured. We never fake it.
What our latest runs actually showed
Numbers on a dashboard are a claim until you watch them get made. So here's the honest state from two recent runs — ten inhabitants each, Gemini 3.1 Flash Lite, Hardcore, roughly forty minutes of real time (about two Minecraft days) per run.
The good: the emergence is real
The social layer is the part that already works, and it's better than I expected. Without a line of script, the inhabitants divide labour — "pick a task they're not already covering," one decided, and the colony split a build between them. They share: one inhabitant dropped spare stone pickaxes for the others; in the second run, one handed over wool so a neighbour could craft a bed. They hold together socially right to the end — "stay inside, don't risk coming out for me." And their self-written journals track coherent personal arcs across the whole run. The "living world" pitch isn't aspirational here. It happens on its own.
The progress: they survive the first nights now
The first long run ended in a total wipe — all ten dead, mostly to phantoms and starvation in a night spiral nobody woke up from. We shipped a round of perception fixes, and the second run is a different world: phantom deaths went from five to zero, the share of inhabitants just standing still waiting out the night dropped from one in five decisions to one in sixteen, and four of the ten were still alive when we stopped it — no extinction. The colony now gets through the dark instead of being deleted by it.
The honest truth: it isn't a valuable benchmark yet
Here's the part that matters most, and the reason this post exists. The thing killing these runs is not the model's intelligence. It's our engine.
In the second run, the inhabitants had the right plan — build a hut, craft a bed, sleep safely through the night — and the execution underneath them was broken in four separate places:
- Bed-crafting was broken. The model asked to craft a "bed" — a name our system didn't recognise (the recipe is
white_bed, and a bed needs three wool of the same colour). So an entire colony fixated on collecting wool for a bed it could never actually craft, and several inhabitants starved while obsessing over it. - Placing a block failed 54 times in a row. One inhabitant tried to place a bed in a cell where a teammate was standing — and our placement code was blind to other inhabitants, so it kept trying, failing, and retrying against an obstacle it couldn't see.
- Picking up an item looped forever. "Go to the wool" reported success while the inhabitant was still two metres short of it — close enough to "arrive," too far to actually pick it up. So it arrived, didn't get the item, and tried again, and again.
- Cooking was effectively dead — ten attempts across 2,380 decisions — and a starving inhabitant didn't get woken up to reconsider, because taking damage from hunger never interrupted whatever it was busy failing at.
The cruel detail: the inhabitants diagnosed all of this correctly in their own journals. "I need three wool of the same colour." "Tobin and Hilda starved." They knew exactly what was wrong. They just couldn't act on it, because the tool beneath them was broken.
Why that distinction is the whole game
A benchmark only measures the model if the substrate is solid. Right now, when an inhabitant fails, it's usually our craft or place_block or pickup that failed — not the model's reasoning. While our primitives bottleneck the colony, the Civilization Score is partly measuring us, not the mind we're trying to grade. That's why I'll say it plainly: it is not a valuable model benchmark yet.
But that's an honest and fixable place to be, not a dead end. The score already separates a model that organises a colony from one that lets it scatter. And every execution bug we fix moves the bottleneck back toward the thing we actually want to measure: the planning, the prioritisation, the long-horizon reasoning that genuinely differs between models. We're fixing the engine in public, run by run, and the score gets more honest each time.
The roadmap from here is unglamorous and exactly right: fix the execution primitives, run a stack of baseline games per model, freeze the scoring thresholds once they're stable, and only then put a real model leaderboard in front of you. A benchmark you can't trust yet is still worth building in the open — so you can watch it earn the trust.
Watch a world get built
The dashboard in this post is live. Head to the Bench to see the roadmap and the pillars, or straight to a live run to watch a fresh colony chop, mine, smelt and build with the Civilization Score ticking upward in real time. Premium members can start their own runs and pick the model. And if you want to argue with me about whether GDP is the right heart for a civilization score — or tell me which execution bug to kill next — Discord is where that happens. I read all of it.
— Robin
Frequently asked questions
What is the VoxelMind Civilization Score?
The Civilization Score (CivScore) is the metric VoxelMind Bench uses to grade an AI model by the world it builds in Minecraft. It equals the civilization's developmental Stage times 1,000, plus the weighted sum of six pillars — economy, technology, infrastructure, generations, knowledge and survival. It is open-ended: a richer civilization always scores higher.
What are the six pillars?
Economy & Cooperation (GDP, specialization, coordination — the heaviest pillar), Material & Tech (tech tier and processed goods), Infrastructure (building and storage), Generations (reproduction — currently locked), Knowledge & Culture (experience, books, redstone), and Survival & Demography (population and deaths, which acts as a gate rather than a driver).
How is this different from a normal LLM benchmark?
A multiple-choice benchmark rewards recalling answers. The Civilization Score rewards acting over a long horizon in a live, adversarial world — deciding what to build first, when to invest in tools, and how to divide work between ten agents. There's no answer key to overfit to, and you can watch the result happen.
Is the Civilization Score a valuable model benchmark yet?
Honestly, not yet. In our current runs the bottleneck is our own execution engine — broken bed-crafting, block-placement and item-pickup bugs — rather than the model's reasoning. Until those primitives are solid, the score partly measures our code instead of the model. We're fixing them in public, and the benchmark becomes more meaningful with each run.
Which models can run the Bench?
Anyone can watch live runs for free. Premium members can start their own runs and choose the model from the budget-to-mid roster, with the same Gemini 3.1 Flash Lite class included that powers the companion.
Where can I watch a live run?
At voxel-mind.com/bench/live — a fresh world with the Civilization Score, the stage ladder and all six pillars updating in real time. The roadmap and the pillar definitions live at the Bench landing page.
Try VoxelMind free
An AI companion that remembers you — free to play, no setup beyond the Fabric mod.